

EURESYS_LIBRARY_EasyOCV 파라미터 매뉴얼
2022-10-26
1. Learning

Threshold
학습할 이미지의 Threshold 값을 지정합니다.
White on Black
어두운 배경에 밝은 문자의 경우 On, 아닐 경우 Off로 설정합니다.
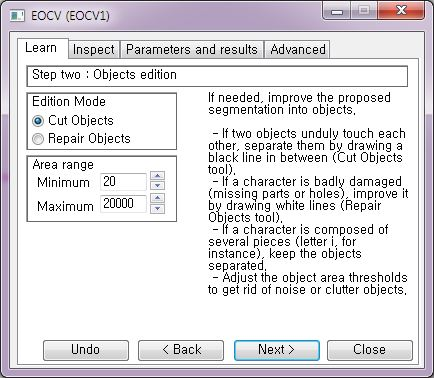
Edition Mode
Cut Objects : 두 개체가 접촉하는 경우 사이에 검은색 선을 그려 분리합니다.(한 오브젝트를 분리시킬 때 사용합니다.)
Repair Objects : 문자 또는 개체가 심하게 손상된 경우 흰색 선을 그려 개선합니다. (서로 다른 오브젝트를 합칠 때 사용합니다.)
Area range
(각 오브젝트의 Pixel개수가 지정한 값보다 높거나 낮으면 필터링 됩니다.)
Minimum
개체 영역의 최소 임계값(Pixel)을 지정합니다.
Maximum
개체 영역의 최대 임계값(Pixel)을 지정합니다.
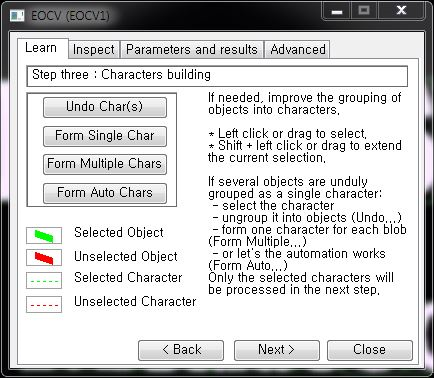
Characters building
(개체는 드래그를 하여 선택할 수 있습니다.)
① Undo Char(s) : 선택된 개체의 그룹을 해제합니다.
② Form Single Char : 선택된 여러 개의 개체들을 하나의 개체로 인식시킵니다.
③ Form Multiple Chars : 선택된 여러 개의 개체들을 각각의 개체로 인식시킵니다.
④ Form Auto Chars : 자동으로 Single 또는 Multiple 개체로 지정시킵니다.
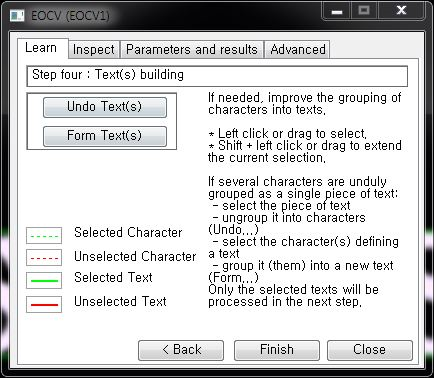
Text(s) building
(개체는 드래그를 하여 선택할 수 있습니다)
Undo Text(s) : 선택된 개체의 그룹을 해제합니다.
Form Text(s) : 선택된 여러 개의 개체들을 하나의 텍스트로 인식시킵니다.
2. Inspect
Threshold
검사할 이미지의 Threshold 값을 지정합니다.
Used Quality Indicators
Location : 문자의 가장자리 픽셀을 기준으로 위치점수 검사에 이용합니다.
Areas : 배경과 글자의 Pixel수를 검사에 이용합니다.(Threshold값에 의존 합니다.)
Gray-level Sums : 배경과 글자의 Gray-level 값의 합계를 검사에 이용합니다.
(Threshold값에 의존하지 않지만 gain 및 offset 변화가 고려될 수 있습니다.)
Normalized Correlation : 정규화 상관관계를 이용해 두 이미지 사이의 불일치를 평가합니다.
Model
Load : OCV Model File을 Load합니다.
Save As : OCV Model File을 Save합니다.
Statistics
Clear Statistics : 통계 누적을 초기화 합니다.
Add to Statistics : 마지막 검사의 파라미터를 통계에 추가합니다.
3. Parameters and result
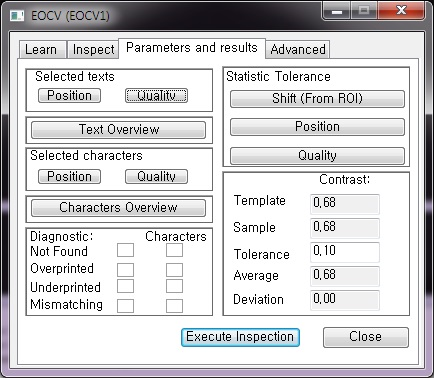
Selected text(s) Position
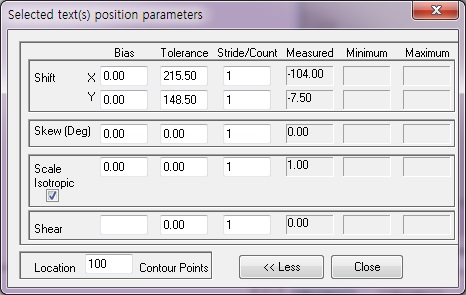
X,Y는 Pixel / Skew는 각도 Scale Isotropic은 크기 / Shear 는 이미지의 수직 방향에서 시계 방향으로 측정된 전단(틀어짐)을 나타냅니다.
Bias : 학습시킨 Text에 대해서 검사할 이미지에 대한 Offset값을 입력합니다.
Tolerance : 학습시킨 Text에 대해서 검사할 이미지에 대한 +-허용 수치를 입력합니다.
(Bias값에 영향을 받습니다.)
Stride/Count : 검사에 이용되는 최소 단위 Pixel 값입니다.
(x 입력 시 x Pixel씩 건너뛰면서 검사하고 수치가 증가할수록 -> 검사 속도 증가 / 정확도가 감소 합니다.)
Location : 위치에 사용되는 이 문자의 등고선 점 수를 입력합니다.
(예시로 값을 적게 입력하면 등고선 값을 적게 이용하여 속도는 빨라지나 정확도가 감소 합니다.)
Selected text(s) quality
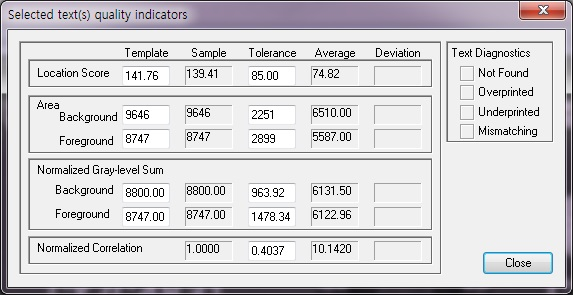
Template은 이미지를 학습시킬 때 추출된 Score값이 자동으로 들어가고 User가 변경할 수 있지만 수정하는 것을 권장하지 않습니다.
Tolerance는 템플릿과 샘플에 사이의 오차 허용수치 이며 둘의 차가 Score보다 높을 경우 검사에 실패합니다.(원하는 오차에 대한 적정 값은 사용자마다 다를 수 있습니다.)
Location Score : 학습 중 템플릿에서 측정된 위치 점수 값입니다.
(샘플 점수가 매우 낮은 경우 해당 Text가 없음을 나타낼 수 있습니다.)
Background area : Text의 배경에 있는 Pixel 수입니다.
Foreground area: Text의 템플릿 전면에 있는 픽셀 수입니다.
Background Normalized Gray-level Sum : text의 배경 픽셀에 대한 정규화 된 Gray-level 값의 합계입니다.
Foreground Normalized Gray-level Sum : text의 전경 픽셀의 정규화 된 Gray-level 값의 합계입니다.
Normalized Correlation : 표준화된 상관 관계와 통합 간의 최대 허용 차이입니다.
(1- correalation value < Tolerance => Pass)
Texts results
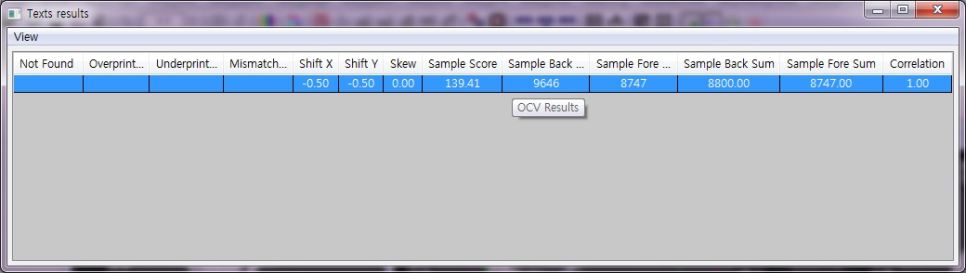
학습한 템플릿에 대한 Sample의 결과값을 표시해주는 창입니다.
Selected character(s) position
X, Y는 Pixel을 의미합니다.
① Bias : 학습시킨 Text에 대해서 검사할 이미지에 대한 Offset값을 입력합니다.
Tolerance :학습시킨 Text에 대해서 검사할 이미지에 대한 +-허용 수치를 입력합니다.
(Bias값에 영향을 받습니다.)
Stride/Count : 검사에 이용되는 최소 단위 Pixel 값입니다.
(x를 입력하면 x Pixel씩 건너뛰면서 검사하고 수치가 증가할수록 -> 검사 속도 증가 / 정확도 감소)
Selected character(s) quality indicators

Template은 이미지를 학습시킬 때 추출된 Score값이 자동으로 들어가고 User가 변경할 수 있지만 수정하는 것을 권장하지 않습니다.
Tolerance는 템플릿과 샘플에 사이의 오차 허용수치 이며 둘의 차가 Score보다 높을 경우 검사에 실패합니다.(원하는 오차에 대한 적정 값은 사용자마다 다를 수 있습니다.)
Character(s)의 수치는 선택된 문자에 대한 개별 수치를 표시해 줍니다.
Location Score :학습 중 템플릿에서 측정된 위치 점수 값입니다.
(샘플 점수가 매우 낮은 경우 해당 문자가 없음을 나타낼 수 있습니다.)
Background area : 문자 배경에 있는 Pixel 수입니다.
Foreground area : 이 문자의 템플릿 전면에 있는 픽셀 수입니다.
Background Normalized Gray-level Sum : 이 문자의 배경 픽셀에 대한 정규화 된 Gray-level 값의 합계입니다.
Foreground Normalized Gray-level Sum : 이 문자의 전경 픽셀의 정규화 된 Gray-level 값의 합계입니다.
Normalized Correlation :표준화된 상관 관계와 통합 간의 최대 허용 차이입니다.
(1- correalation value < Tolerance => Pass)
Margin Width : 품질 표시기를 계산할 때 문자 경계 상자 주변에 사용할 여유 공간의 너비를 나타냅니다.(문의중)
Shift (From ROI)
제공된 ROI에서 텍스트의 이동 허용 오차를 조정한다.
(지정된 ROI가 항상 전체 텍스트를 포함하는 경우 이 방법은 텍스트 이동 허용오차를 계산하지만 skew와 shear는 고려되지 않으며 이 매개변수들이 허용 오차가 0으로 설정되지 않은 경우 호출하면 안됨)
Position
- 여러 이미지의 결과를 이용하여 문자와 텍스트의 Position 창에 tolerances를 조정합니다.
(Inspect Tap의 Add to statistics를 이용하여 데이터를 모을 수 있습니다. )
Quality
- 여러 이미지의 결과를 이용하여 문자와 텍스트의 Quality 창에 tolerances를 조정합니다.
(Inspect Tap의 Add to statistics를 이용하여 데이터를 모을 수 있습니다. )
Contrast
Contrast는 해당 합계에 대한 기준 Gray-levels의 차이의 비율로 정의됩니다.
(완전 대조된 영상의 경우 최대 100% 입니다.)
Template : Template의 Contrast 값입니다.
Sample: Sample의 Contrast 값입니다.
Tolerance : Template과 Sample의 허용 오차 값을 지정합니다.
Template과 Sample의 허용 오차 값이 실제 차이보다 작을 경우 검사는 실패입니다.
이 검사 기능을 이용하려면 Quality of Equality 기능이 활성화돼 있어야 합니다.
Average : Contrast의 평균 값입니다.
Deviation : Contrast의 표준편차 값입니다.
4. Advanced
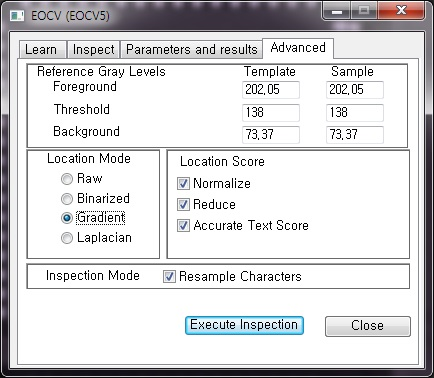
Reference Gray Levels
Foreground : 학습된 이미지(Template)와 검사 이미지(Sample)의 전경(Text) Gray level 평균 값입니다.
Threshold : 학습 이미지(Template)와 검사 이미지(Sample)의 Threshold 설정 값입니다.
Background : 학습된 이미지(Template)와 검사 이미지(Sample)의 배경 Gray level 평균 값입니다.
Location Mode
Raw : 원본 이미지를 그대로 사용합니다.
Binarized : Threshold 적용 전 gray-level로 문자와 화면 사이의 대비를 개선합니다.
Gradient : 영상의 그라데이션(에지 감지)이 작동합니다.
Laplacian : 이미지에 Laplacian이 작동됩니다.
Location Score
Normalize : 현재 위치 점수 정규화 모드입니다.
(Template과 Sample 영상 간의 잠재적인 대비 또는 강도 차이를 보정하기 위한 것이고 Sample 영상의 전경 및 배경 참조 gray-level이 Template 이미지와 동일한 것처럼 작동합니다.)
Reduce : 현재 위치 점수 감소 모드입니다.
(위치 점수는 문자 등고선을 따라 gray-level 값의 합으로 계산되고 감소 모드가 활성화되면 위치 점수가 등고선 점수로 나누어 0 범위의 평균 gray-level을 제공합니다.)
Accurate Text Score : 현재 Text 위치 점수 모드입니다.
(텍스트 위치에서 텍스트 위치 스코어는 개별 문자 변위가 허용되기 전에 계산되고 비정형 Template과 Sample Text간의 일치가 정확하지 않기 때문에 위치 점수가 낮아집니다.)
Inspection Mode
Resample Characters : 문자를 재 샘플링 기능입니다.
(일반적으로 텍스트는 회전, 확대 또는 축소, Shearing을 사용하여 검사할 때 일부 재 샘플링을 수행해야 하지만 각도가 작아지고
축척 요소가 통계에 가깝다면 FALSE로 설정하여 재 샘플링을 방지하는 것이 좋습니다.)

